Indexing and Searching Arbitrary JSON Data using Elasticsearch
If you have ever worked with Elasticsearch, then you are probably familiar with one of the most important features of Elasticsearch - the Dynamic Field Mapping:
By default, when a previously unseen field is found in a document, Elasticsearch will add the new field to the type mapping.
Therefore, if you need to index documents with a high similarity between their field names (dense data), including field types, then this default behavior may be precisely what you want. However, if your documents have a high variation of field names (sparse data) or have the same field names but different types, you will need a different approach.
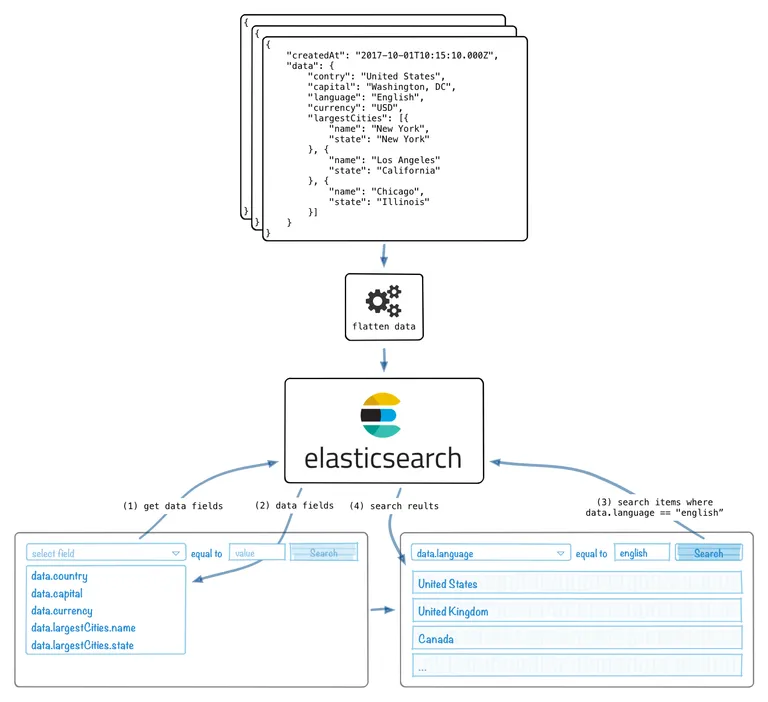
In this post, I would like to show you how to create an Elasticsearch index to index arbitrary JSON data, including data with nested arrays and objects. All this, without exploding the index type mapping with arbitrary properties originating from the indexed data. Nevertheless, the indexed data will still be searchable by any fields, including nested fields, by specifying their path in a "dot" notation format. In addition, I will show how to use Elasticsearch aggregations to fetch a list of all the available fields and their respective types of indexed data.
Dynamic or Strict?
Before we begin, let's see how the default Dynamic field mapping works and what happens when we try to index arbitrary JSON documents. For example, let's try to index the following document into my_index index under my_type type:
Request:
POST /my_index/my_type
{
"data": {
"user": "smnh",
"tags": ["elastic", "search"],
"elasticsearch": {
"version": 5.6,
"currentVersion": true
}
}
}Response:
{
"_index": "my_index",
"_type": "my_type",
"_id": "AV8X9RqXF11pl6w7kdPg",
"_version": 1,
"result": "created",
"_shards": { ... },
"created": true
}Due to Automatic Index Creation and Dynamic Mapping, Elasticsearch creates both my_index index and my_type type with appropriate mapping. We can get the created mapping by executing the following API request:
Request:
GET /my_index/_mapping/my_typeResponse:
{
"my_index": {
"mappings": {
"my_type": {
"properties": {
"data": {
"properties": {
"elasticsearch": {
"properties": {
"currentVersion": {
"type": "boolean"
},
"version": {
"type": "float"
}
}
},
"tags": {
"type": "text",
"fields": {
"keyword": {
"type": "keyword",
"ignore_above": 256
}
}
},
"user": {
"type": "text",
"fields": {
"keyword": {
"type": "keyword",
"ignore_above": 256
}
}
}
}
}
}
}
}
}
}As you can see, Elasticsearch created an Object datatype with three properties, one of which, the elasticsearch, is a nested Object datatype itself. Trying to index more documents with other fields will extend this mapping, eventually making it unreasonably huge. Moreover, indexing a new document with a field already used with a different type will result in an exception. For example, let's try to index a new document, but this time, instead of using float type for the data.elasticsearch.version, we will use a text type:
POST /my_index/my_type:
{
"data": {
"elasticsearch": {
"version": "6.x"
}
}
}Response:
{
"error": {
"root_cause": [
{
"type": "mapper_parsing_exception",
"reason": "failed to parse [data.elasticsearch.version]"
}
],
"type": "mapper_parsing_exception",
"reason": "failed to parse [data.elasticsearch.version]",
"caused_by": {
"type": "number_format_exception",
"reason": "For input string: \"6.x\""
}
},
"status": 400
}Because we have already indexed one document with a float value for the data.elasticsearch.version field, we can not index another document with a different type for the same field. A similar problem will occur if we try to index a document with an array field of different types (assuming coercion is turned off or can not be applied).
Creating an Index
As you have already guessed, we need to turn off the Dynamic field mapping to prevent index type mappings from growing with every newly introduced field. And with a bit of effort, we can define an index mapping that will allow us to index documents with high variation of field names, including documents with fields of different types or fields with arrays of different value types.
The idea for this solution mainly comes from this elastic.co blog post. The idea is to create a list of objects with predefined fields holding the flattened keys and values of the original data. Continuing our previous example, instead of indexing the original document, we could index the following document:
{
"data": { ... original document ... }
"flatData": [
{
"key": "user",
"type": "string",
"key_type": "user.string",
"value_string": "smnh"
},
{
"key": "tags",
"type": "string",
"key_type": "tags.string",
"value_string": ["elastic", "search"]
},
{
"key": "elasticsearch.version",
"type": "float",
"key_type": "elasticsearch.version.float",
"value_float": 5.6
},
{
"key": "elasticsearch.currentVersion",
"type": "boolean",
"key_type": "elasticsearch.currentVersion.boolean",
"value_boolean": true
}
]
}In this document, every object in the flatData array represents a leaf node in the original document and has the following fields:
key: the path of the field in the original documenttype: the type of the field valuekey_type: thekeyand thetypeconcatenated by a"."(for faster aggregations)value_{type}: the field value. The name of this field is created by concatenating the string"value_"with the value of thetypefield (e.g.,value_string,value_float,value_long, etc.).
Notes:
- The original document is included inside the
datafield to be stored and returned with the_sourcefield, although it will not be indexed. On the other hand, theflatDatafield will be indexed but not stored inside the_sourcefield. - Had the
tagsarray included values of different types, then its values would have been separated and grouped within objects by their types.
To index a document of this type, we will need to create an index with an appropriate mapping. Assuming our new index will be called my_index and our document type will be called my_type, the index creation request will look like this:
PUT /my_index
{
"settings": {
"index": {
"mapper.dynamic": false
}
},
"mappings": {
"my_type": {
"dynamic": "strict",
"_source": {
"excludes": ["flatData.*"]
},
"properties": {
"data": {
"type": "object",
"enabled": false
},
"flatData": {
"type": "nested",
"properties": {
"key": {
"type": "keyword",
"include_in_all": false
},
"type": {
"type": "keyword",
"include_in_all": false
},
"key_type": {
"type": "keyword",
"include_in_all": false
},
"value_string": {
"type": "text",
"fields": {
"keyword": {
"type": "keyword",
"ignore_above": 256
}
}
},
"value_boolean": {
"type": "boolean"
},
"value_date": {
"type": "date"
},
"value_long": {
"type": "long"
},
"value_float": {
"type": "float"
},
"value_null": {
"type": "boolean",
"null_value": false,
"include_in_all": false
}
}
}
}
}
}
}- The
settings.index.mapping.dynamicisfalseto disable automatic type creation. It is not necessary for the purpose of this post, but I do like to make things as strict as possible. - The
mappings.my_type.dynamicisstrictto disable the automatic creation of properties onmy_typetype. This is how we turn off the Dynamic field mapping. - The
mappings.my_type._source.excludesis set to["flatData.*"]to ensure that theflatDataobject and its flattened fields will not be included in the stored_sourceobject. The_sourcealready includes the original document inside thedatafield, so there is no reason to store this data twice. - The
datafield that stores the original document is of the Object datatype. Theenabledflag of this property is set tofalseto ensure that it will be completely ignored and therefore will not be parsed and indexed. Although it will be stored inside the document's_sourcefield. - The
flatDataobject is of Nested datatype (click the link to learn why this property must be of this type). As previously seen, this object is derived from the original data by flattening its keys. The flattening procedure is described in the following section. - The
keywordfield is a multi-field having theflatData.value_string.keywordpath and thekeywordtype. This allows analyzing and indexing the value of theflatData.value_stringas akeywordfor exact value searches. - The
value_nullfield is a special field for storingnullvalues. Elasticsearch does not store null values, therefore in order to be able to query fornullvalues, we need to define a separate field with null_value parameter. In our case, thenullvalue will be represented byflatData.value_nullof abooleantype with afalsevalue.
Flattening the Data
The data flattening procedure is not complicated. It is less than 100 lines of code. The following Gist includes the flattenData function. This function receives an object and flattens it into an array of objects, having the same format as we have seen before. The following section explains the high-level logic behind this function.
Loading gist https://gist.github.com/smnh/30f96028511e1440b7b02ea559858af4
Every value is an array
Elasticsearch indexes all document fields as multi-value fields. Therefore it does not have a dedicated array type. As a matter of fact, every type is an array of values of that type. Thus, the flattening process does not indicate the presence of arrays to the field path (i.e., the key property).
For example, given the following data:
{
"tags": ["elastic", ["search"]]
}The flattened data will look like this:
[{
"key": "tags",
"type": "string",
"key_type": "tags.string",
"value_string": ["elastic", "search"]
}]The key property is tags, the type property is a string, and the value_string is an array of strings. Hence, there is no indication that the original value had a nested array. Let's take a look at another example:
{
"tags": "elastic search"
}This data will be flattened into a similar object:
[{
"key": "tags",
"type": "string",
"key_type": "tags.string",
"value_string": "elastic search"
}]Note: as noted previously, from the Elasticsearch perspective, a single value is semantically identical to an array with a single element. Therefore we could wrap the
"elastic search"string with an array and get the exact same result.
In the last example, although its value_string holds a single string instead of an array of two separate strings, Elasticsearch will analyze and index this document exactly in the same way as it will do with the document from the previous example. The only exception is that the former document's flatData.value_string.keyword field will have two separate terms. In contrast, the latter document will have only one term - the original "elastic search" string.
Grouping fields values by path and type
Field values having the same paths and types are grouped into single arrays. This perfectly aligns with how Elasticsearch indexes arrays of nested objects.
For example, the following data:
{
"versions": [
{
"version": "4.4",
"name": "KitKat"
},
{
"version": "5.0",
"name": "Lollipop"
},
{
"version": "6.0",
"name": "Marshmallow"
}
]
}Will be flattened as:
[
{
"key": "versions.version",
"type": "string",
"key_type": "versions.version.string",
"value_string": ["4.4", "5.0", "6.0"]
},
{
"key": "versions.name",
"type": "string",
"key_type": "versions.name.string",
"value_string": ["KitKat", "Lollipop", "Marshmallow"]
}
]Splitting arrays by paths and types
As opposed to the previous rule, arrays with multi-type values, or field values with the same paths but different types, will be split into separate arrays grouped by type.
{
"tags": ["elastic", "search", 5.5, 5.6]
}[
{
"key": "tags",
"type": "string",
"key_type": "tags.string",
"value_string": ["elastic", "search"]
},
{
"key": "tags",
"type": "float",
"key_type": "tags.float",
"value_float": [5.5, 5.6]
}
]Scalar values have empty keys
If the data is a scalar value or is an array of scalar values, the key property for these values will be an empty string.
For example:
["elastic", {"search": "is great"}]Will be flattened into:
[
{
"key": "",
"type": "string",
"key_type": ".string",
"value_string": ["elastic"]
},
{
"key": "search",
"type": "string",
"key_type": "search.string",
"value_string": ["is great"]
}
]Extensive example
data:
let flatData = flattenData({
"key1": "value1",
"key2": true,
"key3": {
"key3_1": 1,
"key3_2": 2.2,
"key3_3": "2015-01-01"
},
"key4": [
"value2", "value3", 4, 5,
{"key7": "value4"},
{"key7": "value5"},
{"key7": 6.1},
{"key7": ["value6", 6.2]}
]
});flatData:
[
{
"key": "key1",
"type": "string",
"key_type": "key1.string",
"value_string": "value1"
},
{
"key": "key2",
"type": "boolean",
"key_type": "key2.boolean",
"value_boolean": true
},
{
"key": "key3.key3_1",
"type": "long",
"key_type": "key3.key3_1.long",
"value_long": 1
},
{
"key": "key3.key3_2",
"type": "float",
"key_type": "key3.key3_2.float",
"value_float": 2.2
},
{
"key": "key3.key3_3",
"type": "date",
"key_type": "key3.key3_3.date",
"value_date": "2015-01-01T00:00:00.000Z"
},
{
"key": "key4",
"type": "string",
"key_type": "key4.string",
"value_string": ["value2", "value3"]
},
{
"key": "key4",
"type": "long",
"key_type": "key4.long",
"value_long": [4, 5]
},
{
"key": "key4.key7",
"type": "string",
"key_type": "key4.key7.string",
"value_string": ["value4", "value5", "value6"]
},
{
"key": "key4.key7",
"type": "float",
"key_type": "key4.key7.float",
"value_float": [6.1, 6.2]
}
]Getting the Available Field Names and Types
Having our arbitrary data indexed, we now want to know which fields and types exist in the index. This kind of information may be used to build queries and execute searches. For example, we can create a dynamic user interface that allows creating a query by selecting a field name from the list of available field names. Then, based on the selected field name, the UI can present a dropdown box with all the available types for the selected field. And based on the selected field type, it can then present a dropdown box with an operator selector and an input field to enter a value.
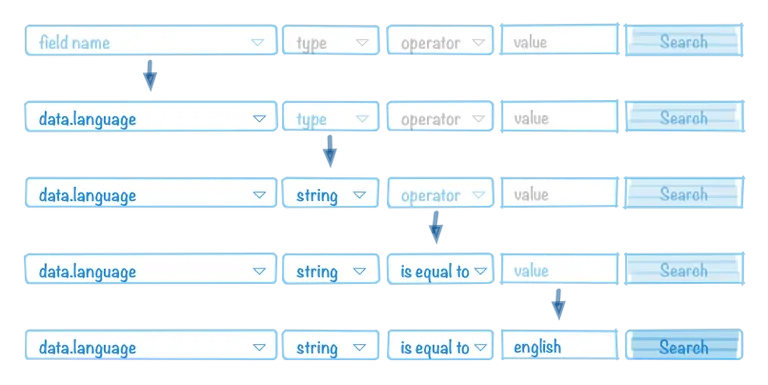
To get the available fields and their types in the indexed documents, we can use Elasticsearch Aggregations. Because we have indexed every field with key and type properties, we can aggregate all the needed data by using three-level deep nested aggregation:
A Terms Aggregation over the type field, nested in another Terms Aggregation over the key field, nested inside another Nested Aggregation over the flatData field.
If the indexed documents do not have a high variation of types per field, instead of having
typeaggregation nested insidekeyaggregation, a singlekey_typeaggregation may be used. The returnedkey_typevalues should be split by the last.(dot character) to get thekeyandtypeof the fields.
Example:
POST /my_index/my_type/_search:
{
"size": 0,
"aggs": {
"dataFields": {
"nested": {
"path": "flatData"
},
"aggs": {
"keys": {
"terms": {
"field": "flatData.key",
"size": 50
},
"aggs": {
"types": {
"terms": {
"field": "flatData.type",
"size": 10
}
}
}
}
}
}
}
}Result:
The aggregation result is pretty extensive, so I've cleaned some non-relevant properties, but technically it will have the following structure:
{
...
"aggregations": {
"dataFields": {
"keys": {
"doc_count_error_upper_bound": 0,
"sum_other_doc_count": 0,
"buckets": [
{
"key": "user",
"types": {
"buckets": [
{
"key": "string",
...
}
],
...
},
...
},
{
"key": "elasticsearch.version",
"types": {
"buckets": [
{
"key": "string",
...
},
{
"key": "float",
...
}
],
...
},
...
},
...
]
},
...
}
}
}Note: if the
sum_other_doc_countis greater than zero, it means that some of the fields were not returned. In this case, thesizeof theflatData.keyaggregation should be bigger to ensure that all of the fields will be returned.
We can wrap this logic inside a single function which will return all the available fields in a "dot" notation format:
getDataFields().then(result => {});The result will be an array of objects having two fields:
key: field path in a "dot" notation formattypes: array of all the types this field might have in the same document or across multiple documents.
[
{"key": "user", "types": ["string"]},
{"key": "tags", "types": ["string", "float"]},
{"key": "elasticsearch.version", "types": ["string", "float"]},
{"key": "elasticsearch.currentVersion", "types": ["boolean"]},
]Searching by Field Names and Types
Now that we have all the field names and types in the indexed data, we can create and execute search queries. If we want to search by a specific field, every search query should contain a bool query with a must clause having at least two queries. First is a term query for matching the field name (the flatData.key property), and the second is any other query for matching the actual value. It may be a match, term, range, or any other query that may fit the specific case.
For example, if we would like to find all the documents having the elasticsearch.version field of type string equal to 6.x, we would execute the following query:
{
"query": {
"nested": {
"path": "flatData",
"query": {
"bool": {
"must": [
{"term": {"flatData.key": "elasticsearch.version"}},
{"match": {"flatData.value_string": "6.x"}}
]
}
}
}
}
}